This is a peculiar post about a nice little DNS service I came across few days ago. While reviewing a pull request I came across an address along the lineshttps://192.168.1.56.nip.io & I couldn’t find an immediate clarification and searching I could find the Github repo of the project but I couldn’t understand how it worked.
Later our DevOps engineer had to explain to in detail on what this is and how it works !
The nice little utility service has per-created wild card DNS entries for the entire private IP address range. Queries like NOTEXISTING.192.168.2.98.nip.io will get resolved to 192.168.2.168
This is a very useful trick if we don’t want to edit /etc/hosts or equivalent for tools or software running locally or for scenarios where a DNS record is required.
When I first started working on software applications nearly 2 decades ago, the norm was a user interface connecting to a db and presenting the end user with means to interact with the database. If I remember correctly the first application in the traditional client-server sense that I came across was Mailman. (Looks like the application is heavily rebranded and still around! ). The general idea was any software (desktop or web) can connect with a database using a database driver and work. Things have changed a lot and various API like techniques were introduced enabling faster development cycles and near infinite scalability.
Modern applications uses numerous methods to provide APIs. The shift from RPC, SOAP and even from REST is quite interesting. While RESTful APIs and techniques like OpenAPI specifications are still quite popular, we are moving away to more modern methods. Some ideas like using PostREST is around, GraphQL seems to be the most developer friendly mechanism available.
GraphQL
The GraphQL is a different approach and unlike a typical API, its more of a language that can query and end point. Behind the screens there can be a database and a service can run in-front of the db exposing a URL for querying various data points. Unlike traditional APIs provided by RESTful services etc, the GraphQL method needs just one end point and it can provide different types of responses based on the queries. In addition to this there are numerous advantage like the responses being typed.
Querying the Blockchain
The blockchain technology introduced by Bitcoin is now more than a decade old. But the blockchain implementations generally struggle with providing an easy way to query their blocks/data. Its quite normal to have traditional databases to hold much large amounts of data compared to blockchains but the databases always perform better when one attempt to query them.
Since its inherently difficult to query the blockchain (database), most projects provide means to stream data to a database. Applications often called as dApps essentially calls this “centralized” databases to understand the information on the blockchain. Modern blockchains like Ethereum, Polkadot etc has understood this problem and implemented interfaces to easily consume the data.
[ from: EIP-1767: GraphQL interface to Ethereum node data ]
Ethereum for example has introduced GraphQL support in addition to JSON RPC via EIP-1767. On Polkadot ecosystem there are multiple projects like Hydra, Subquery implementing indexing and exposing GraphQL end points.
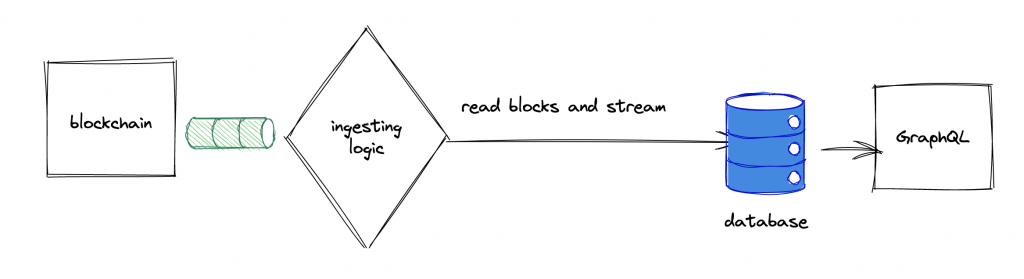
In general the GraphQL solutions in the blockchain space looks as follows:
The Graph
The Graph Project, ie https://thegraph.com/en/ is attempt to build a SaaS product and attempt to bring in some level of decentralization via providing a method to run indexer nodes by multiple parties. They have a stacking system and people can run servers as indexers fetching and exposing GraphQL endpoints. While this might be interesting, I want to focus on the technical aspects.
The Graph project has implemented a “listener” to fetch data from various chains like Ethereum, Polkadot and others. This data is then pushed into a PostgreQL database. The team is using IPFS too, but just to store the schema and configuration files (looks like something done to justify the decentralization buzzword ?). The next step in the equation is a GraphQL server which exposes and end point for the external world.
The code for the indexer node is here https://github.com/graphprotocol/graph-node/tree/master/server/index-node
Browsing the code also gave insights to StreamingFast and firehose projects which used by the Graph Project. From a quick read, StreamingFast seems to be a protocol to read the blocks and pack them to into file like data structure and efficiently stream across the network. Looks like a fast and efficient method to stream the data from the chains to external databases.
Why use The Graph project ?
For aspiring blockchain projects to provide modern and easy methods for the dApp developers, getting associated with the project could be beneficial. Its definitely possible to self host a data ingestion tool to push the data into a database and then a software like Hansura to provide GraphQL. But being part of a project which aims at decentralizing the APIs can help in resilience and more visibility. There is some information here on on boarding https://thegraph.com/migration-incentive-program/ [Disclaimer: I am not a user or part of the graph project in anyway and this is not a recommendation to use the product, token or any of their programs ]