This is a peculiar post about a nice little DNS service I came across few days ago. While reviewing a pull request I came across an address along the lineshttps://192.168.1.56.nip.io & I couldn’t find an immediate clarification and searching I could find the Github repo of the project but I couldn’t understand how it worked.
Later our DevOps engineer had to explain to in detail on what this is and how it works !
The nice little utility service has per-created wild card DNS entries for the entire private IP address range. Queries like NOTEXISTING.192.168.2.98.nip.io will get resolved to 192.168.2.168
This is a very useful trick if we don’t want to edit /etc/hosts or equivalent for tools or software running locally or for scenarios where a DNS record is required.
When I first started working on software applications nearly 2 decades ago, the norm was a user interface connecting to a db and presenting the end user with means to interact with the database. If I remember correctly the first application in the traditional client-server sense that I came across was Mailman. (Looks like the application is heavily rebranded and still around! ). The general idea was any software (desktop or web) can connect with a database using a database driver and work. Things have changed a lot and various API like techniques were introduced enabling faster development cycles and near infinite scalability.
Modern applications uses numerous methods to provide APIs. The shift from RPC, SOAP and even from REST is quite interesting. While RESTful APIs and techniques like OpenAPI specifications are still quite popular, we are moving away to more modern methods. Some ideas like using PostREST is around, GraphQL seems to be the most developer friendly mechanism available.
GraphQL
The GraphQL is a different approach and unlike a typical API, its more of a language that can query and end point. Behind the screens there can be a database and a service can run in-front of the db exposing a URL for querying various data points. Unlike traditional APIs provided by RESTful services etc, the GraphQL method needs just one end point and it can provide different types of responses based on the queries. In addition to this there are numerous advantage like the responses being typed.
Querying the Blockchain
The blockchain technology introduced by Bitcoin is now more than a decade old. But the blockchain implementations generally struggle with providing an easy way to query their blocks/data. Its quite normal to have traditional databases to hold much large amounts of data compared to blockchains but the databases always perform better when one attempt to query them.
Since its inherently difficult to query the blockchain (database), most projects provide means to stream data to a database. Applications often called as dApps essentially calls this “centralized” databases to understand the information on the blockchain. Modern blockchains like Ethereum, Polkadot etc has understood this problem and implemented interfaces to easily consume the data.
[ from: EIP-1767: GraphQL interface to Ethereum node data ]
Ethereum for example has introduced GraphQL support in addition to JSON RPC via EIP-1767. On Polkadot ecosystem there are multiple projects like Hydra, Subquery implementing indexing and exposing GraphQL end points.
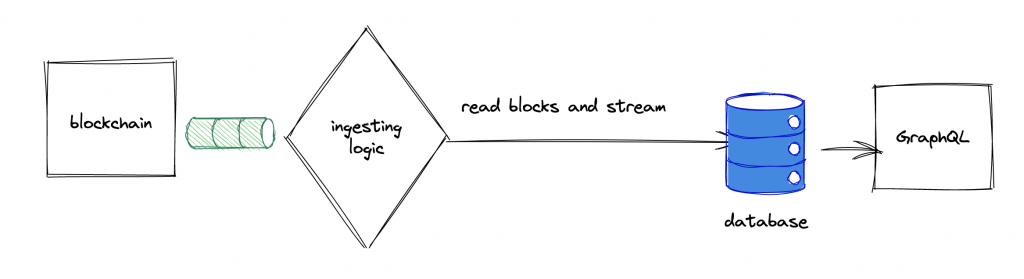
In general the GraphQL solutions in the blockchain space looks as follows:
The Graph
The Graph Project, ie https://thegraph.com/en/ is attempt to build a SaaS product and attempt to bring in some level of decentralization via providing a method to run indexer nodes by multiple parties. They have a stacking system and people can run servers as indexers fetching and exposing GraphQL endpoints. While this might be interesting, I want to focus on the technical aspects.
The Graph project has implemented a “listener” to fetch data from various chains like Ethereum, Polkadot and others. This data is then pushed into a PostgreQL database. The team is using IPFS too, but just to store the schema and configuration files (looks like something done to justify the decentralization buzzword ?). The next step in the equation is a GraphQL server which exposes and end point for the external world.
The code for the indexer node is here https://github.com/graphprotocol/graph-node/tree/master/server/index-node
Browsing the code also gave insights to StreamingFast and firehose projects which used by the Graph Project. From a quick read, StreamingFast seems to be a protocol to read the blocks and pack them to into file like data structure and efficiently stream across the network. Looks like a fast and efficient method to stream the data from the chains to external databases.
Why use The Graph project ?
For aspiring blockchain projects to provide modern and easy methods for the dApp developers, getting associated with the project could be beneficial. Its definitely possible to self host a data ingestion tool to push the data into a database and then a software like Hansura to provide GraphQL. But being part of a project which aims at decentralizing the APIs can help in resilience and more visibility. There is some information here on on boarding https://thegraph.com/migration-incentive-program/ [Disclaimer: I am not a user or part of the graph project in anyway and this is not a recommendation to use the product, token or any of their programs ]
Cross chain (Inter Blockchain communication) projects have been something I have been working for last 2+ years now. Transfer of assets from Bitcoin to Graphene like chains have been the essential focus. Right now on the second project on Peerplays, we have purely decentralized Bitcoin Asset Transfer nearing completion.
SONs
SONs aka Sidechain Operator Nodes are democratically elected, decentralized Bitcoin Gateways. The gateways are not just decentralized, we can also extend them to support other chains like EOS, Ethereum, Hive etc.
We are looking at only the transfer of assets or value. This means, records and contracts (smart-contracts) will not be transferred.
High Availability
One of the peculiar aspects is the usage of blockchain itself to do
the heart beats to ensure the uptime. With 15 minimum number of nodes
working in a decentralized manner and handshaking is our biggest
challenge.
I had https://pivpn.dev/ successfully running for a while withuot any issues. Then suddenly it stopped working. The configuration was never received on various devices. Unfortunately there was absolutely no information anywhere – no logs, search results returned big essays on OpenVPN.
There is a little handy command which can actually fix the issues in a moment.
Go to the VPN server and just run pivpn -d
Running the pivpn command with -d option fixes most of the issues.
Its diagnosis will be printed to the screen.
=============================================
:::: Self check ::::
:: [OK] IP forwarding is enabled
:: [OK] Ufw is enabled
:: [OK] Iptables MASQUERADE rule set
:: [OK] Ufw input rule set
:: [OK] Ufw forwarding rule set
:: [OK] OpenVPN is running
:: [OK] OpenVPN is enabled (it will automatically start on reboot)
:: [OK] OpenVPN is listening on port 1194/udp
=============================================
:::: Snippet of the server log ::::
=============================================
:::: Debug complete ::::
:::
::: Debug output completed above.
::: Copy saved to /tmp/debug.txt
I had setup Pi-hole, a remote one, DNScrypt, both local and remote, privoxy for cleaning up the bad web traffic that passes through pi-hole etc. Things were looking good and that’s when EFF came up with their new https://panopticlick.eff.org/
After all the effort, the Panopticlick reports are not shining with colors. This gives and idea about the extend to which tracking is prevalent.
The funny part is, this is what you you get with all the circus !!
I was looking at the possibility of staying at an Himalayan Village for a while and working. Interestingly, I stumbled up a training firm called Alt-Campus : https://altcampus.io/
Clockwise from top: Skyline of Dharamsala, Main Street Temple – McLeod Ganj, Gyuto Karmapa, Himachal Pradesh Cricket Association Stadium and St. John church (Image from https://commons.wikimedia.org/wiki/File:Dharamsala_Montage.png)
Yes, the cool thing is that they have setup this up in Dharmasala!
They seem to have an hands on training which could be useful. The payments are only after one get placed and that sounds pretty cool thing to do as well.
I will post more details, if I find anything new …. !
Featured image from : https://en.wikipedia.org/wiki/Dharamshala#/media/File:Cloudy_Triund,_above_Mcleod_Ganj,_Himachal_Pradesh.jpg
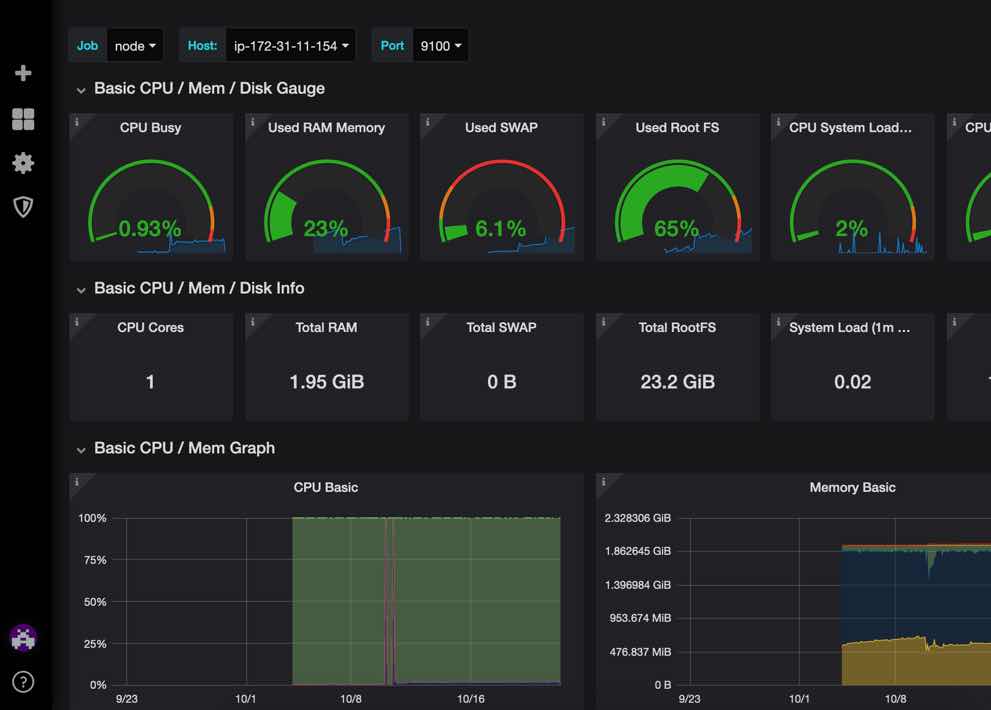
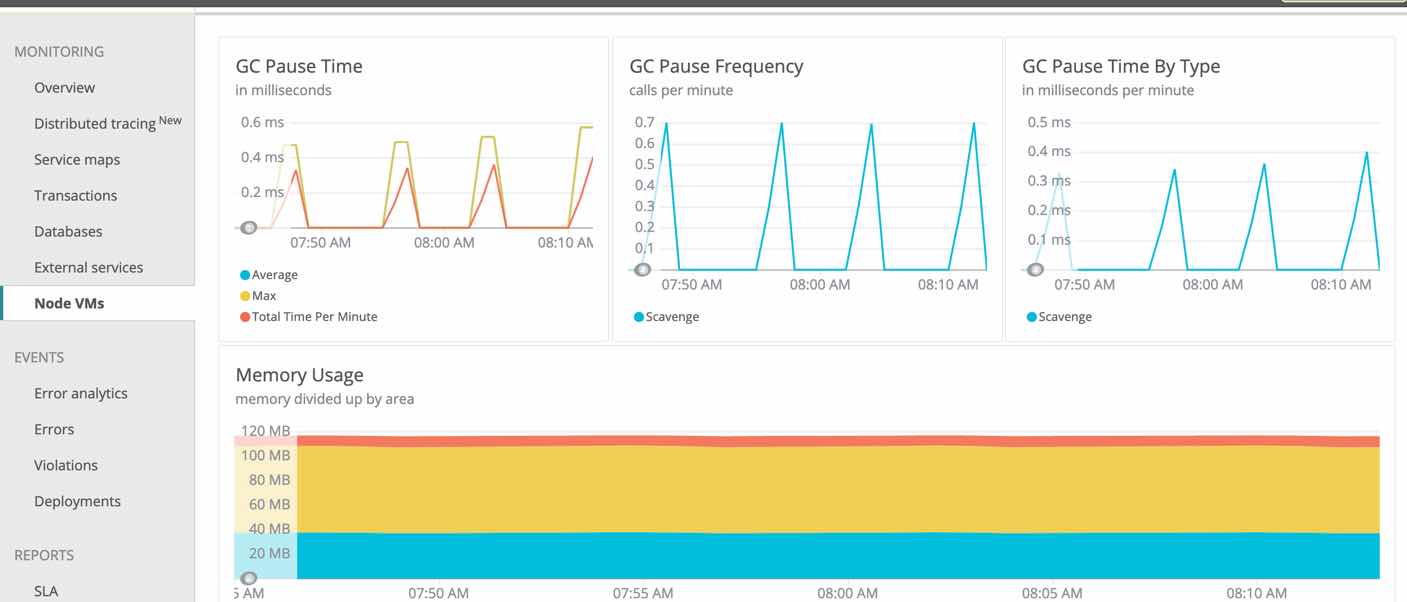
As someone from a C++ – Java – UNIX background Javascript on the server side was always a peculiar thing for me. For the current application https://streamersedge.com/ dApp combining blockchain, video streaming, games NodeJS has become a very important tool chain.
For the performance, a questionnaire of the sort is prepared. Publishing it here as I would like to save them and also get some critics from the experts.
The eventual plan is to use Prometheus, Grafite, Grafana stack for Metrics and ELK (ElasticSearch, Logstack, KibanaO for log aggregation. We are also experimenting with some APMs like Newrelic in the meantime.
NodeJS VM Garbage collection
What is the GC (garbage collection) parameters we have ?
How heap size/RAM is available for the NodeJS process ?
Are we using all the CPUs available on a given server or instance ?
What are the sysctl and process security limits for the NodeJS processes in a given server/instance ?
Have we optimized the network connections to the servers to support maximum connections ?
For given CPU and RAM, say, 1 Ghz and 1 GB RAM, roughly how many concurrent connections we can support ?
Are we running I/O bound NodeJS processes ? (This is when DevOps will show your BPF super powers ? :slightly_smiling_face: )
OpenTracing – Can we use Grafana – ELK to map the CPU spikes ?
Newrelic / Dynatrace or an Open Source solution for APM ?
Writing code is a tedious process as it involves many conditions. Often the programmers miss out scenarios which can result in bugs (rainy day scenarios). Another common scenario missed out is optimizing the code for space and time complexity (efficiency). The programmers will be busy trying to address the problem at hand and many a times they miss on optimizing.
When we have Peer code reviews, this can be improved. Having few issues with the code is fine but not having code reviews is not acceptable in any software development team.
Static Code Analysis
In simple terms this method is to assess the behavior of the code by performing lexical, syntax analysis as well as other advanced means. Control flow & Data flow analysis are also performed. Findbugs for Java is to a well established example.
Security considerations are one of the major aspects that static code analysis often targets. OWASP wiki entry on static code analysis is an excellent starting point to learn more.
Linting
Some of the basic static code analyzers are called Linters. Though there is no hard and fast rule to call a certain code analyzer as linting tool I think its safe to assume that the coding standard checkers can be called as a linting tool. The term is originated from a static code analyzer called “Lint”.
Code Review tools
The process of code review is quite tedious and as the complexity of the project increases, this gets tougher. There are numerous tools that helps developers to conduct effective code reviews. With the advent of Continuous Integration, its lot more easier to incorporate code review in an automated fashion. Once the automatic code review is done, its essential to report the issues in a easily addressable way.
New generation Project management and Source Control Management Software like Gitlab integrates automation of the review, CI and CD in an innovative manner.
A Gitlab repository which is a CI + CD back end for a Github project.
In addition to the modern all-in-one platforms, there are obviously tools like Reviewboard and others which is focused on the code review alone.
Review Board an excellent, dedicated code review tool.
Phabricator
Meet Phabricator – an excellent project management & source code management platform. The platform has a powerful CLI interface which makes it the swiss army knife of Software Development Process.
Well, I have not heard about it, who uses it ?
Honestly this is the most frequent comment I have heard about Phabricator. So here is a list of users:
Wikimedia Foundation – yea, that small website guys!
Facebook
Asana.com
Blender (https://developer.blender.org/)
KDE
then of-course, yours faithfully!
I rest my case.
In my opinion, Phabricator is the best project management and source hosting platform existing with its unique code review features, CLI tools etc. When it comes to CI and CD, phabricator is not the best and with tools like Gitlab and we just have to mirror Phabricator hosted repository and take care of the CI and CD. Needless to say, Phabricator also supports Subversion and Mercurial. Since they provide a powerful programmable API, it may be even possible to integrate with other code management solutions like Preforce.
Arcanist
This section is about arcanist & is intended for users who are new to it or know about it but haven’t set it up anytime.
Arcanist aka arc is the command line tool which is provided by Phabricator to help with code reviews, merging etc. In a nutshell, we can raise a code review, with pre-defined static code analysis and rules using this powerful tool.
There are four sections of this article:
What is it?
Which features can we use?
Why should we bother?
Quick start guide
What is it ? Arcanist basically works on top of tools like Git, Differential, Linter etc and provides command line interface to them. It is a code review and revision management utility.
Which features can we use ?
lint
diff
land
anoid
Why Should we bother ?
Lint: Wouldn’t it be nice if someone could look into your code and point out syntax errors, wrong use of constructs, use of undeclared variable and many more ? It turns out that there are tools which do this exact work and are referred to as Lint. It also simplifies code review process for the reviewer as well as the author
Diff: Working on a project and not sure whether the changes made are ready to be pushed? This is where diff comes into play. If using Git, arc diff sends all commits in a range for review. By default, this range is
git merge-base origin/master HEAD..HEAD
Land: If the review raised through gets accepted, then we use arc land to publish the changes.
Quick Start Guide
Supported on: Linux, Mac OS X, Windows, FreeBSD & there is a quick way to setup anywhere with NixOS.
The one liner install on macOS and Linuxes using the awesome Nix package manager :
Try typing ‘arc’, if it shows usage exception, then we are good so far.
To set up tab completion add the following to you PATH environment variable source /path/to/arcanist/resources/shell/bash-completion Example:- source /home/user/phabricator/arcanist/resources/shell/bash-completion
Configuring arc for a project :
This section assumes that you have a Phabricator installation at https://phabricator.steem.io
Goto project directory
Create a file with name ‘.arcconfig’ (without quotes)
Paste the following in the file. {"phabricator.uri" : "https://phabricator.steem.io"}
Run arc install-certificate and follow the instructions.
The commands could be used in this sequence:
arc lint –> arc diff –> arc land
arc lint
Setting up lint :
1. Create a file with name ‘.arclint’ in project directory 2. Detailed documentation for setting up .arclint can be found here.
Example of .arclint file:-
{
“linters”: {
“lint”: {
“type”: “pep8”,
“include”: “(\.py$)”
}
}
}
“lint” –> this is a custom name given by you, it doesn’t affect anything.
“type” –> to specify the linter we would like to use.
“include” –> regex for the format of files to lint.
“exclude” –> can be used to exclude files matching include tag in specific directories.
arc diff
First time while using this command, it will ask for access token which can be obtained by following the instructions.
Specify Test plan, reviewers and proceed.
A review request can be updated any number of times before it has been reviewed or separate reviews can be raised using arc diff –create arc land Once a review gets accepted, the changes can be published using this command. It is the last step in the standard Differential pre-publish code review workflow. arc anoid
Extended read: arc tasks, arc browse.
Encouragement
The Phabricator command line tooling sounds little weird when we first read the documentation. But once you setup, which is very fast if you follow the documentation as it is, its very powerful. The tools are written in PHP7.X and don’t be concerned, its blazing fast. I have been extensively using it, even to review documents. ie, instead of Google Doc, Tracking via Mircorsoft word’s tracking etc.
A sample document under review.
Summary
As already mentioned, test-driven, peer-reviewed code is the only acceptable way to develop software. Code review tools like Phabricator’s inbuilt tools are highly recommended irrespective of the tooling, language that a developer is using.
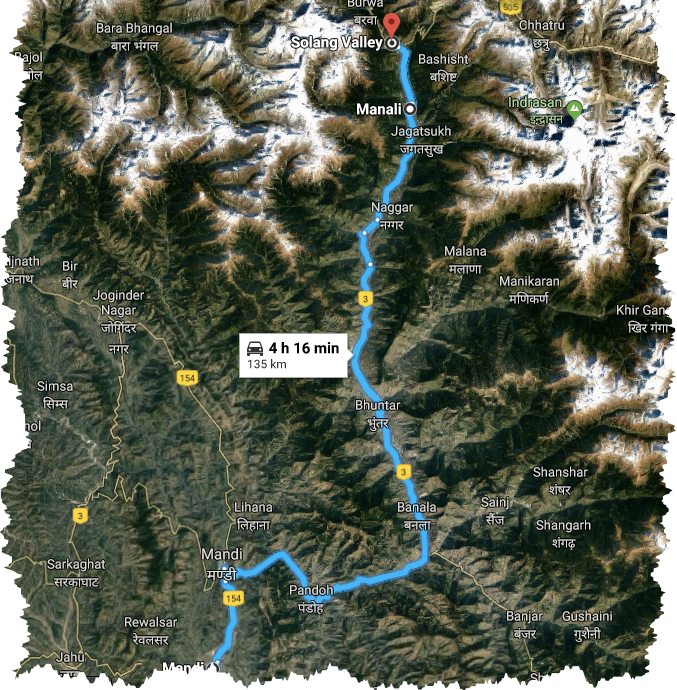
From December 26th 2018 to January 4th 2019 we were traveling and the general destination was Himachal Pradesh. The Northern, mountainous state of India.
https://cdn.steemitimages.com/DQmUudGrSQYMmZdissJ9wuuoWuV4X1PZEkxYugByqX1nBZ8/image.png
Due to certain training my cousin had to attend, 4 of us travelled to New Delhi First and from there to a small city in Himachal Pradesh called Mandi.
https://cdn.steemitimages.com/DQmdUscEaoT4QfTcATXRDkRT8dsGzYCZKoLFJDKHXQbe6n8/image.png
Mandi is 850 m (2,790 ft) above Mean Sea Level and for us who are traveling from “the sea Level” itself, this provided a good 1 day halt for acclimatization and rest.
(Beas River, Mandi, Himachal Pradesh, India)
Our original plan was to travel to Tirthan Valley from Mandi. But my cousin and family wanted to see snow and @firepower suggested Solang Valley as the right place. Myself was not very particular about the location and @firepower’s suggestion turned out to be very good as everyone seemed to be heading there and every weather prediction service showed snow during the time we were there.
Solang Valley
The Solang village which near Manali is where the Beas River flowing through a valley forms the valley of adventure sports – The Solang Valley. Its unbelieving crowded for a small village. One can find few hundred shops renting snow equipment, mountain bikes (ATB), couple of hundred ponys and a charade of vehicles.
As we neared Manali endless traffic block started appearing and we crawled and crossed Manali in few hours. The temperature had dropped to probably 3 or 4 degree Celcius. We had hotel booked in advance through an online service called MakeMyTrip.com & I had tried to confirm our arrival delay via SMS. There was no response from the hotel and considering it as a bad sign and seeing the unprecedented traffic I finally called the hotel. The person at the hotel was somewhere with loud music and all I could comprehend was the rooms are ready.
The adventure begins
Few minutes later, I got a call back from the hotel. The call was not audible but I felt something wrong. Tried again and after many tries the call was audible and the hotel person lazily explained that the rooms are sold out. I tried to explain I had updated them in the morning and I have a receipt from MakeMyTrip. At this point the hotel proprietor said, if we had booked the ticket through MakeMyTrip, talk to them and not to the hotel. I politely asked him to please try to talk to MakeMytrip – the hotel person wanted us to stop or go-back to Manali & take accommodation in a stay in Manali.
So, everything was crystal clear. We had booked at the hotel quite early at a nominal (yes, very nominal rate). And here we were on the Christmas – New Year season where the rates can be anything. People were probably trying to optimize their occupancy.
We never found out whose mistake it was. We only knew that we had not done anything wrong.
Sensing trouble, I asked my wife who was not traveling with me to call MakeMyTrip & arrange a call back. Simultaneously I called MakeMyTrip.com from another phone. So, after few minutes, I managed to explain the MakeMytrip representative what is going on. He agreed to check with the hotel and call back. He took the booking ID and other relevant details. So, I waited for the call back. Few minutes later the first call back arrived from MakeMyTrip & they explained, there is nothing to worry and I just have to go there and check-in the hotel. Few minutes into the conversation, the second call back arrived. The representative bluntly explained that the hotel is sold out ! So I asked him what happened to the booking we did – to which again he said, the hotel is sold out. All this while, I had the other MakeMyTrip executive on the different phone explaining that everything is in order.
Travels are one of the best teachers who gives us lessons which no one else can give
I must say, it was fun to put the executives on speaker and tell them that the calls are on recording and they are contradicting each other. This was my turn to wear the cold and bruteless hat, thus I said, “MakeMyTrip.com has offered us the hotel booking and we are now standing in near zero temperatures. We don’t have the rooms and 4 lives are in the hands of MakeMyTrip”. The representatives both agreed to help out.
Rest of the few kilometers we sat down and relaxed.
The hotel
We reached Solang Valley and entered the hotel where we had our rooms booked. The person at the reception promptly received us and he was looking into the booking details. Few moments later the owner of the hotel came and he was looking at the details as well as if nothing happened. Then, he asked in whose name the booking is – this time, I had to give the booking details. We looked at each other & with after considerable delay the hotel owner said, we spoke little while ago. I said, Yes we did. After he explaining that the rooms are sold out, I told them to talk to the online portal whose booking software had auto-magically sent me booking confirmation.
## Failed Startups helps Entrepreneurs!
This is something I realized just now while I was writing this. It so happned that I was fortunate or unfortunate to start mybusticket.com few years before a popular Indian bus ticketing service called RedBus.in and then loosing out to them. I also had adventures into travel by the name of Routez.Travel. While we waited for the call back, I was thinking about how travel industry worked, about those APIs and services which makes hotel bookings, flight bookings etc possible. Thanks to RECCAA.Club, I knew about hospitality management software as well.
The much awaited call back from MakeMytrip arrived and I must mention that the executive was professional and one of the most proactive customer care executives I have ever came across.
So, we talked about travel industry, travel booking software, acquisitions done by GoIbibo, acquisitions done by MakeMyTrip and pretty much everything about travel industry other than flight bookings!
The executive explained to me that he will try his level best to arrange a hotel either at this one or elsewhere. I handed over the phone to the the hotel owner and this time the discussions were about GoIbibo-MMT panel and “Nancy” & many other irrelevant things. The phone was back to me and I clearly said, the life of 4 of us is with MakeMyTrip. Both the hotel and the MakeMyTrip representative requested to wait for 15 minutes.
The hotel owner offered us tea & showed us 2 rooms which by then got “cancelled”. The tea was a life saver as the cold and walking on crystallized snow had started impacting me. The MakeMyTrip representative had kept his word and called back and explained a nearby hotel which was perhaps the best in the Valley. He explained even the minute details and left the decision to me. I asked him to talk to my hotel owner once again and see whether the newly appeared rooms can be arranged. As this is normal incident in touristy areas, I just wanted to play along than make a scene. The hotel owner wanted 3 times the normal price from MakeMyTrip. To my surprise, the MakeMyTrip owned the situation and offered to do anything as per my wish. I asked for the MakeMyTrip’s representative & decided to go with the hotel he suggested. He went ahead and make all the required arrangements.
When we finally walked in to the hotel that MakeMyTrip had arranged, we were surprised to find a Swiss cottage which costed 5 times our original room. The manager at “Sky one Ski” Mr Hemanth welcomed us as if to his own home & made us comfortable.
The adventure was not over!
The online Portal MakeMyTrip and its executives had done and excellent job to serve us. But our dear friend at the hotel directed to the wrong location when asked about the new location. My physical state due to the extreme weather had clouded my thinking and instead of cross checking the new hotel location we decided to walk there. Due to the confusions, we walked close to 1 km in the chilling cold over the slippery ice and reached the hotel. There was no power anywhere and after a while we realized that our “hotel” guy had sent us to a different hotel with similar name. Helpless, we walked back and found “Sky one Ski” with the help of helpful localities. Our driver was very helpful as sympathetic as well.
The Swiss Tent
Sky one Ski has marvelous facilities and well equipped Swiss Tents. The property is tucked inside an apple orchard.
(Inside the Beautiful Tent)
(The Apple Orchad)
While we had the most luxurious hotel – thanks to the travel operator – power and the climate was not the best. Unfortunately there was no power and we had only 1 tent instead of 2 rooms. We had a bunch of candles which we used to heat the tent and tucked inside the blankets (Duet) with our 3 layer clothing, jackets and gloves. The altitude though it was only 10,000 feet (3000 meters), was acting on us, the weather by then – 10 degrees presented us with a chilling experience. Thanks to the hotel guy who gave priority to few pennies over the well being of guests, there we were sleeping under the sky, in a luxurious Swiss Tent, separated from the freezing weather by 2 layers of cloth and 3 Candles.
Thanks to MakeMyTrip and the extremely helpful staff at “Sky one Ski” we woke up to another morning alive and tell this story.
(inside the swiss tent – Sky one Ski)
(The beautiful view at the morning – thanks to Mr Sivankar of MakeMyTrip.com, Mr Hemanth of Sky one Ski & Our Driver, Mr Vinod. You guys are one of the best professionals I have met & wishing you all the very best)